People-Ojbect Interaction Dataset

Introduction
The people-object interaction dataset comprises 38 series of 30-view multi-person or single-person RGB-D video sequences, complemented by corresponding camera parameters, foreground masks, SMPL models and some point clouds, mesh files. Each video sequence boasts a 4K resolution, 25 FPS, and a duration of 1~19 seconds. All 30 views are captured using Kinect Azure devices in a uniformly surrounding scene. Github repository of our dataset is https://github.com/sjtu-medialab/People-Ojbect-Interaction-Dataset.
Video Sequences Collection and Post Processing
We designed the collecting environment and system as shown below.

Details of collected video sequences are show below.
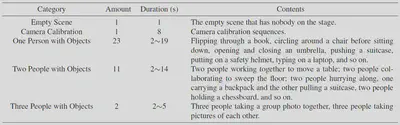
For the post processing, we use BackgroundMattingV2 to extract foreground masks, methods of Zhou et al. and Zhou et al. to extract point clouds and mesh files, MMHuman3D to extract SMPL models.
Dataset Download
The name of subfolders in Meshes and Point Clouds are defined by:
4D_seriesname_frameindex,
where the seriesname corresponds to the name of subfolders in RGB-D-Mask Sequences, the frameindex are the frame index the meshes, and point clouds are constructed for.
-
Our dataset is available for free and academic research only, no commercial use.
-
You can access our File Share or Dropbox or BaiduNetdisk(百度网盘) with verify code of ‘sjtu’, to download video sequences of the dataset. Contact Admin Donghui Feng for any questions.
Copyright (c) 2024, Shanghai Jiao Tong University. All rights reserved.
Camera parameters
Camera parameters can be found in https://github.com/sjtu-medialab/People-Ojbect-Interaction-Dataset. Camera parameters are provided in the intrinsic.txt and extrinsic.txt. Extrinsics of our cameras are in the format of camera coordinate system to world coordinate system.
Citation
If you find our dataset useful in your research and you want to cite our dataset, please refer to https://github.com/sjtu-medialab/People-Ojbect-Interaction-Dataset.
Li Song
Professor, IEEE Senior Member
Professor, Doctoral Supervisor, the Deputy Director of the Institute of Image Communication and Network Engineering of Shanghai Jiao Tong University, the Double-Appointed Professor of the Institute of Artificial Intelligence and the Collaborative Innovation Center of Future Media Network, the Deputy Secretary-General of the China Video User Experience Alliance and head of the standards group.