Chinese HD Talking Face Database

Introduction
The CHDTF dataset is a large-scale dataset for Chinese natural dialogue video clips. The dataset contains 1,000,000 video clips, collected from the internet and contains a wide variety of scenes and topics, with a total duration of 1,000 hours. The dataset is designed for training and evaluating lip synthesis models. The dataset is annotated with audio-video synchronization information and lip synchronization error scores. The dataset is designed for training and evaluating lip synthesis models.
Data Source and Collection
To make the dataset more in line with one of the currently interesting application fields of lip synthesis technology, the short video synthesis on the internet, publicly available short videos from Douyin and youlai.cn platforms were collected and aggregated by community volunteers as the original video sources for the dataset. Raw data files remain in the format including resolution and frame rates as it is after downloaded.
Data Standardization and Conversion
The raw video files are renamed using a 32-byte lower letter hash digest of the file content to avoid duplicate files. The video files are converted to the MP4 format using h264 codec with a frame rate of 25fps. The audio track of the video is converted to the WAV format with a sampling rate of 16kHz. Videos that have an original frame rate lower than 25fps, resolution lower than 720p, or length shorter than 15s or longer than 1000s are discarded. All conversion operations are performed using FFmpeg. After the standardization and conversion, the raw video files then were turned into a raw dataset, with standard file name rules and video&audio format for further processing.
Data Preprocessing
The 25fps mp4 videos with 16kHz WAV audios are then processed by the following steps to generate the final dataset of valid clips.
Sound Track Separation
Web videos are usually accompanied by background music, which is not suitable for this dataset purpose. Therefore, we use the open source tool (python-audio-separator, using the amazing MDX-Net models from UVR) as spleeter to separate the human audio track of the video into two tracks, one for the human voice and the other for the background music. The human voice tracks were retained and the background music tracks were discarded. The human voice tracks were in WAV format with a sampling rate of 16kHz.
Clip Extraction
The video is then divided into clips using a Voice Activity Detection (VAD) algorithm. The VAD algorithm, based on the open-source tool Silero-VAD, detects the start and end times of the human voice in the video. Clips are created based on these time intervals, with a maximum length of 10 seconds. Clips with a human voice shorter than 0.6 seconds are discarded. The audio quality of the clips is assessed using Signal-to-Noise Ratio (SNR), and clips with an SNR lower than 17dB are also discarded. The SNR quality check is based on the open source tool SNR-Estimation-Using-Deep-Learning.
Face Detection And Tracking
The clips are then checked for the presence of human faces. The open-source model S3FD detects human faces in the clips. Faces were detected for every frame in the clips and tracked. The faces were tracked by an IOU-based tracker. The face in the next frames with an IOU higher than 0.5 is considered the same face. Clips with no human faces detected in the first frame are discarded. The detected faces are then tracked across the frames of the clips. Clips are discarded if they do not contain a face track that is longer than 15 frames and also exceeds half of the total number of frames in the clip.
Clip Audio-Video Offset Detection
The audio and video tracks of the clips are then checked for synchronization. The audio and video tracks of the clips are analyzed using the open-source tool SyncNet to obtain audio-video offsets and confidence scores including LSE-C. The audio and video offsets are recorded carefully but not corrected, avoiding the introduction of additional errors. Preprocessing is necessary for the training usage.
Clip Validation
The clips that have audio-video offset larger than 2 frames are removed, regardless of whether the audio is ahead or behind the video. Also, any clips after the audio-video offset detection that have an LSE-C score lower than 3 are discarded. If the minimal face size of any dimension is less than 200, the video clip is also discarded.
After all of those procedures, the final dataset is generated, with the following features:
- 25fps mp4 video clips with 720p resolution with 16khz sampling rate wav audio
- 0.6s to 10s duration with human voice of SNR higher than 17dB
- face track validated and minimum face size of any dimension larger than 200
- audio-video offset less than 2 frames and LSE-C score higher than 3
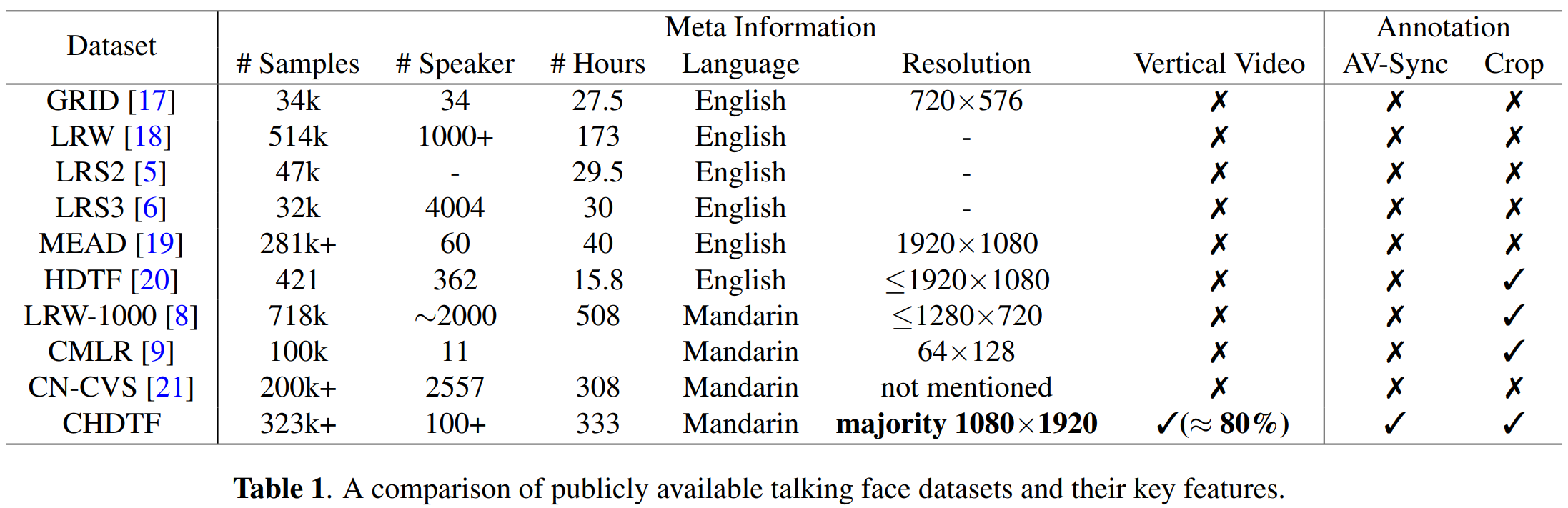
Comparison with Existing Dataset
Acknowledgement
Special thanks to Zhen Guo for being the community founder of this project and data collection and for coordinating and managing the community volunteers’ work. Our gratitude goes to Miao Feng and FireKeeper for their professional algorithm and technical advice. Thanks to Jeffstreic at Hangzhou Perseus Technology Co. LTD for his community program management role, and to chj113 for his assistance with community project management. And we appreciate the significant computational resources and active participation of Yunxiang Chen, Jun Wen at Guangzhou New Sansong Digital Technology Co., Ltd., and Xu An at UE TECHNOLOGY.
Download
Our dataset is permitted for academic research ONLY, with no commercial use.
To access the datasets created/assembled by Shanghai Jiao Tong University, please complete and sign this license [agreement]. Subsequently, email it to Prof. Li Song (using “CHDTF public datasets availability and download credentials” as the e-mail subject) to receive the link for downloading.
Copyright (c) 2024, Shanghai Jiao Tong University. All rights reserved.
Li Song
Professor, IEEE Senior Member
Professor, Doctoral Supervisor, the Deputy Director of the Institute of Image Communication and Network Engineering of Shanghai Jiao Tong University, the Double-Appointed Professor of the Institute of Artificial Intelligence and the Collaborative Innovation Center of Future Media Network, the Deputy Secretary-General of the China Video User Experience Alliance and head of the standards group.